Overview
TaskingAI-Inference is an autonomous backend service featuring a Unified API aimed at facilitating the smooth integration of Large Language Models (LLMs) and Text Embedding models from various providers. It acts as a bridge, enabling users to effortlessly access and utilize an extensive selection of LLMs. This service employs asynchronous techniques to ensure efficient and high-performance LLM inference.
The project is open-source on GitHub.
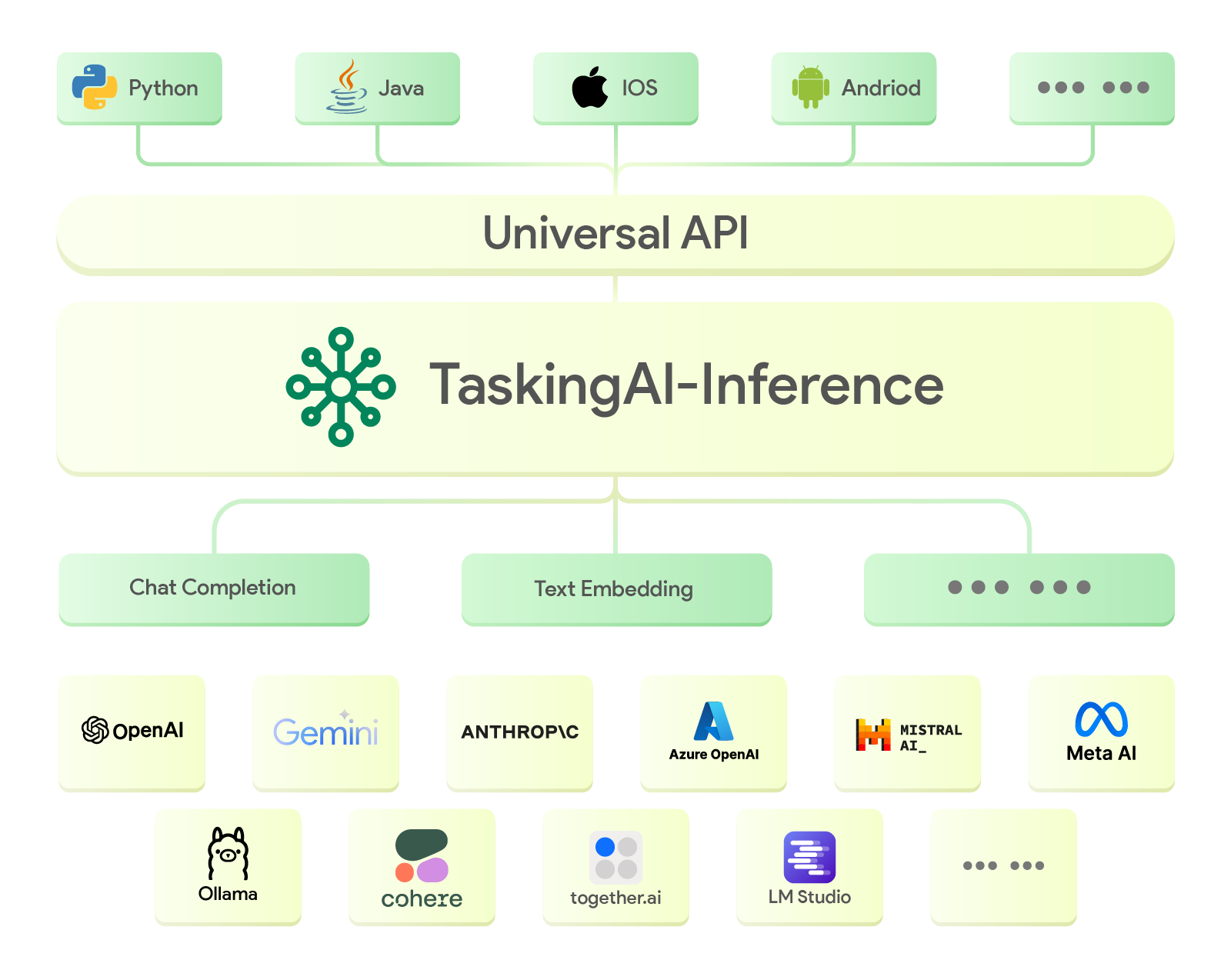
Key Features
-
Unified API Integration: Offers seamless integration of a variety of mainstream Large Language Models (LLMs) into the TaskingAI platform through unified APIs, enabling easy access and deployment.
-
Function Call Support: Enables LLMs to interact with external resources through supported function calls, expanding their usability and integration capabilities.
-
Asynchronous Requests for High-Concurrency: Designed to handle high-concurrency scenarios efficiently through the support of asynchronous requests, ensuring performance stability.
-
End-to-End Encryption: Ensures the security of data and API keys with robust end-to-end AES encryption, safeguarding credential information.
-
Custom Hosted Model Support: Allows users to deploy custom models locally and integrate them into the TaskingAI-Inference service for seamless access and deployment.
Supported Models
For a full list of supported models and their required credentials, please refer to Providers and Models.