LM Studio
If your tasking AI server is locally deployed with Docker, and the target model is also running in your local environment, LM_STUDIO_HOST should start with http://host.docker.internal:port instead of http://localhost:port. Replace port with your actual port number.
LM Studio is a development environment designed to provide a feature-rich platform for developers working with large language models.
Requisites
To integrate a model running on LM Studio to TaskingAI, you need to have a valid LM Studio service first. To get started, please visit LM studio's website, or follow the simple instructions in the Quick Start.
Required credentials:
- LM_STUDIO_HOST: The url to the model running on LM Studio. Should ends with port number, detailed endpoint path is not required. For example,
http://localhost:1234
Supported Models:
Wildcard
- Model schema id: lm_studio/wildcard
Quick Start
Deploy LM Studio service to your local environment
- Download LM Studio client from LM studio's website.
- Launch the client.
- Search and download your desired model
- Load your model using LM Studio.
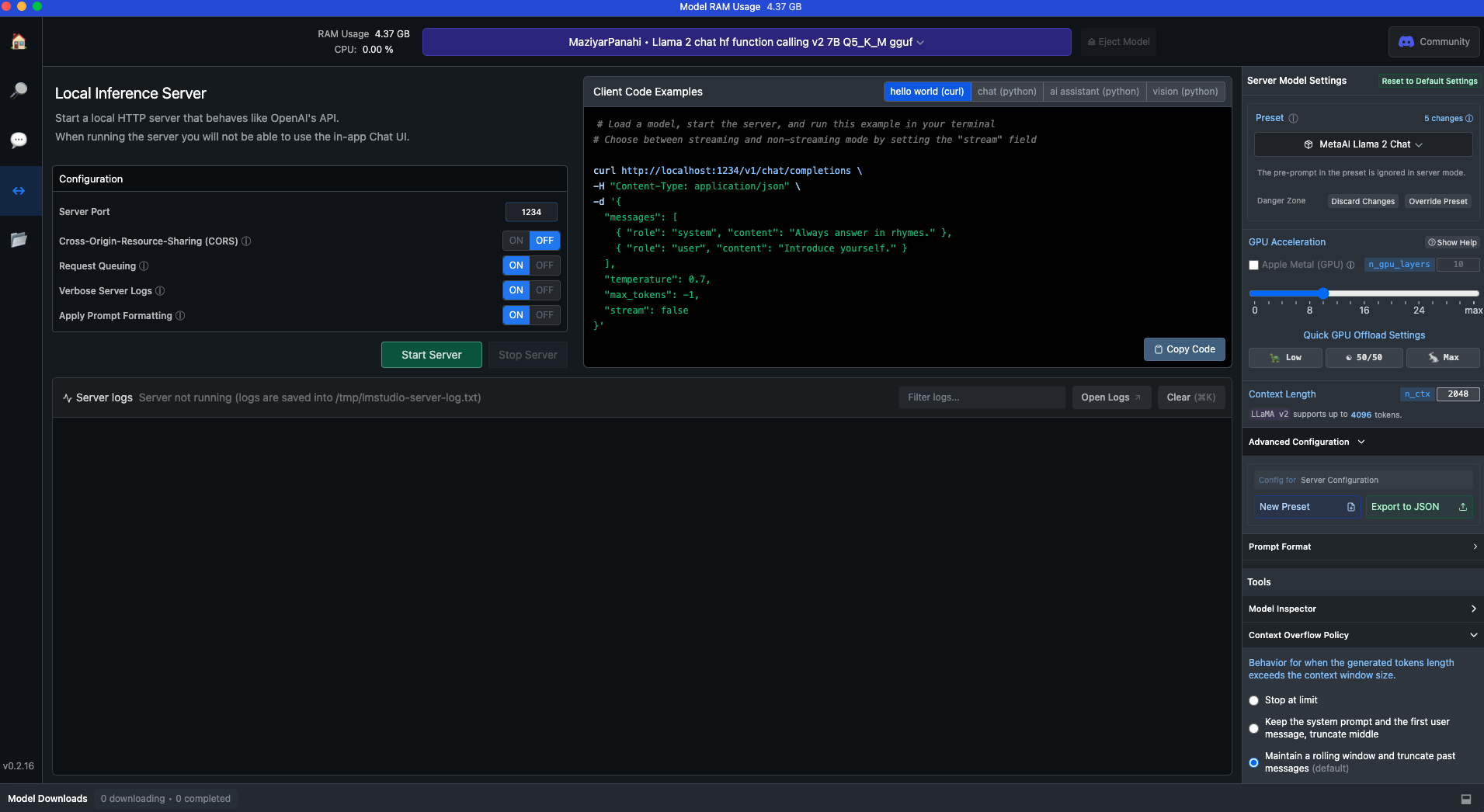
By default, the model is running on your localhost at 1234 port. And you should pass http://localhost:1234 as LM_STUDIO_HOST to TaskingAI.
Integrate LM Studio to TaskingAI
Now that you have a running LM Studio service with your desired model, you can integrate it to TaskingAI by creating a new model with the following steps:
- Visit your local TaskingAI service page. By default, it is running at
http://localhost:8080. - Login and navigate to
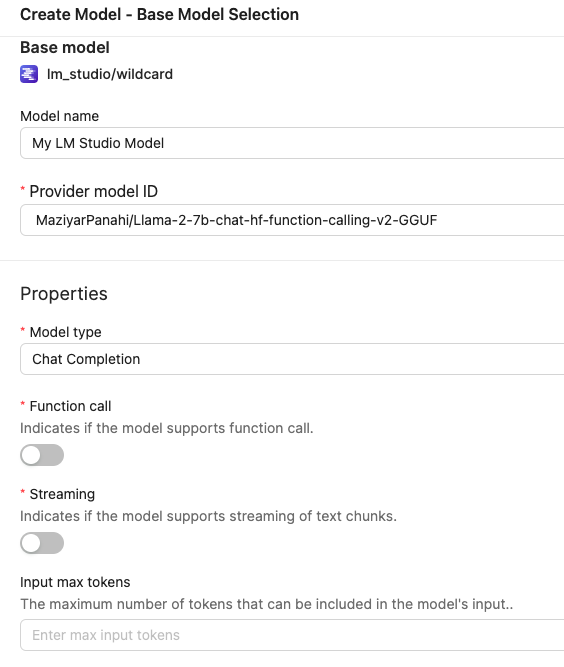
Modelmanagement page. - Start creating a new model by clicking the
Create Modelbutton. - Select
LM Studioas the provider, andwildcardas model. - Use LM Studio host's address
http://localhost:1234asLM_STUDIO_HOST. Or if you are running the model on a different port, replace1234with the correct port number. - Input the model name and
provider_model_id. Theprovider_model_idis the name of your desired model.